Pandas - Veri Düzenleme Yöntemleri
Cum 15 Temmuz 2022Düzenleme Yöntemleri
Sütun Ekle
Veri çerçevesine yeni bir sütun ekleyip bu sütuna değer atamak mümkündür. Bunu şu yöntemle yapabiliriz.
Veri_Çerçevesi_Adı["Yeni_Sütun_Adı"] = Atanacak_Değerler
Örneğin NBA oyuncularının çeşitli bilgilerinin bulunduğu veri çerçevesinden, yıllık kazanç miktarlarını (Salary) 12'ye bölerek aylık kazançlarını hesaplayarak, Aylık Kazanç isimli yeni sütuna yazmaya çalışalım. Önce Veri çerçevemizin orijinal haline göz atalım.
veri = pd.read_csv("Veri_Setleri/nba.csv")
print(veri)
| Name | Team | Number | Position | Age | Height | Weight | College | Salary | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Avery Bradley | Boston Celtics | 0.0 | PG | 25.0 | 6-2 | 180.0 | Texas | 7730337.0 |
| 1 | Jae Crowder | Boston Celtics | 99.0 | SF | 25.0 | 6-6 | 235.0 | Marquette | 6796117.0 |
| 2 | John Holland | Boston Celtics | 30.0 | SG | 27.0 | 6-5 | 205.0 | Boston University | NaN |
| 3 | R.J. Hunter | Boston Celtics | 28.0 | SG | 22.0 | 6-5 | 185.0 | Georgia State | 1148640.0 |
| 4 | Jonas Jerebko | Boston Celtics | 8.0 | PF | 29.0 | 6-10 | 231.0 | NaN | 5000000.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 453 | Shelvin Mack | Utah Jazz | 8.0 | PG | 26.0 | 6-3 | 203.0 | Butler | 2433333.0 |
| 454 | Raul Neto | Utah Jazz | 25.0 | PG | 24.0 | 6-1 | 179.0 | NaN | 900000.0 |
| 455 | Tibor Pleiss | Utah Jazz | 21.0 | C | 26.0 | 7-3 | 256.0 | NaN | 2900000.0 |
| 456 | Jeff Withey | Utah Jazz | 24.0 | C | 26.0 | 7-0 | 231.0 | Kansas | 947276.0 |
| 457 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
458 rows × 9 columns
Şimdi istediğimizi yapmaya (yıllık kazanç miktarlarını (Salary) 12'ye bölerek aylık kazançları, Aylık Kazanç isimli yeni sütuna yazmaya) sıra geldi.
veri["Aylık Kazanç"] = veri["Salary"] / 12
print(veri)
| Name | Team | Number | Position | Age | Height | Weight | College | Salary | Aylık Kazanç | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Avery Bradley | Boston Celtics | 0.0 | PG | 25.0 | 6-2 | 180.0 | Texas | 7730337.0 | 644194.750000 |
| 1 | Jae Crowder | Boston Celtics | 99.0 | SF | 25.0 | 6-6 | 235.0 | Marquette | 6796117.0 | 566343.083333 |
| 2 | John Holland | Boston Celtics | 30.0 | SG | 27.0 | 6-5 | 205.0 | Boston University | NaN | NaN |
| 3 | R.J. Hunter | Boston Celtics | 28.0 | SG | 22.0 | 6-5 | 185.0 | Georgia State | 1148640.0 | 95720.000000 |
| 4 | Jonas Jerebko | Boston Celtics | 8.0 | PF | 29.0 | 6-10 | 231.0 | NaN | 5000000.0 | 416666.666667 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 453 | Shelvin Mack | Utah Jazz | 8.0 | PG | 26.0 | 6-3 | 203.0 | Butler | 2433333.0 | 202777.750000 |
| 454 | Raul Neto | Utah Jazz | 25.0 | PG | 24.0 | 6-1 | 179.0 | NaN | 900000.0 | 75000.000000 |
| 455 | Tibor Pleiss | Utah Jazz | 21.0 | C | 26.0 | 7-3 | 256.0 | NaN | 2900000.0 | 241666.666667 |
| 456 | Jeff Withey | Utah Jazz | 24.0 | C | 26.0 | 7-0 | 231.0 | Kansas | 947276.0 | 78939.666667 |
| 457 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
458 rows × 10 columns
Satır ya da Sütun Sil
Veri çerçevesine ekleme yapılabildiği gibi, silme / çıkarma işlemi de yapılabiliyor. Bunun için drop() metodu kullanılıyor.
drop() Fonksiyonu
Bu metodun kullanım/yazım şekli aşağıdaki gibidir.
Veri_Çerçevesi_Adı.drop("Satır ya da Sütun Adı", axis = 0 ya da 1, inplace = True/False)
- Satır ya da Sütun Adı, adından belli olduğu üzere, silinecek sütunun adıdır. Birden fazla sütun silinmek istenirse, isimler liste şeklinde yani köşeli parantez içinde yazılmalıdır.
axis Parametresi
Sıfır (0) Satırları, Bir (1) Sütunları temsil eder. Varsayılan (default) değeri 0'dır. Aynı isme ait satır ve sütun bilgisi olması durumunda, bu parametre satırın mı, sütunun mu silinmesi gerektiği konusunda bize yardımcı olur.
inplace Parametresi
Gerçekleştirilen silme işleminin veri çerçevesinde kalıcı ya da geçici olmasını ayarladığımız kısımdır. inplace = True yazılırsa, yapılan işlem kalıcı hale gelecektir.
NBA oyuncularının bilgilerinin bulunduğu veri çerçevesinden, Yaş (Age) bilgisini silmeye çalışalım.
veri.drop("Age", axis = 1, inplace=True)
print(veri)
| Name | Team | Number | Position | Height | Weight | College | Salary | Aylık Kazanç | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Avery Bradley | Boston Celtics | 0.0 | PG | 6-2 | 180.0 | Texas | 7730337.0 | 644194.750000 |
| 1 | Jae Crowder | Boston Celtics | 99.0 | SF | 6-6 | 235.0 | Marquette | 6796117.0 | 566343.083333 |
| 2 | John Holland | Boston Celtics | 30.0 | SG | 6-5 | 205.0 | Boston University | NaN | NaN |
| 3 | R.J. Hunter | Boston Celtics | 28.0 | SG | 6-5 | 185.0 | Georgia State | 1148640.0 | 95720.000000 |
| 4 | Jonas Jerebko | Boston Celtics | 8.0 | PF | 6-10 | 231.0 | NaN | 5000000.0 | 416666.666667 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 453 | Shelvin Mack | Utah Jazz | 8.0 | PG | 6-3 | 203.0 | Butler | 2433333.0 | 202777.750000 |
| 454 | Raul Neto | Utah Jazz | 25.0 | PG | 6-1 | 179.0 | NaN | 900000.0 | 75000.000000 |
| 455 | Tibor Pleiss | Utah Jazz | 21.0 | C | 7-3 | 256.0 | NaN | 2900000.0 | 241666.666667 |
| 456 | Jeff Withey | Utah Jazz | 24.0 | C | 7-0 | 231.0 | Kansas | 947276.0 | 78939.666667 |
| 457 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
458 rows × 9 columns
Gördüğünüz gibi veri çerçevemizde artık Oyuncuların Yaş bilgilerini barındıran Age isimli sütun bulunmuyor, tamemiyle silindi.
Birden fazla satır ya da sütun silmek istediğimiz zaman silinmesini istediğimiz satır ya da sütun isimlerinin (ya da indeks değerlerini) liste olarak yani köşeli parantez içerisinde belirtmemiz gerekir.
veri.drop(["College", "Number"], axis = 1, inplace=True)
print(veri)
| Name | Team | Position | Height | Weight | Salary | Aylık Kazanç | |
|---|---|---|---|---|---|---|---|
| 0 | Avery Bradley | Boston Celtics | PG | 6-2 | 180.0 | 7730337.0 | 644194.750000 |
| 1 | Jae Crowder | Boston Celtics | SF | 6-6 | 235.0 | 6796117.0 | 566343.083333 |
| 2 | John Holland | Boston Celtics | SG | 6-5 | 205.0 | NaN | NaN |
| 3 | R.J. Hunter | Boston Celtics | SG | 6-5 | 185.0 | 1148640.0 | 95720.000000 |
| 4 | Jonas Jerebko | Boston Celtics | PF | 6-10 | 231.0 | 5000000.0 | 416666.666667 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 453 | Shelvin Mack | Utah Jazz | PG | 6-3 | 203.0 | 2433333.0 | 202777.750000 |
| 454 | Raul Neto | Utah Jazz | PG | 6-1 | 179.0 | 900000.0 | 75000.000000 |
| 455 | Tibor Pleiss | Utah Jazz | C | 7-3 | 256.0 | 2900000.0 | 241666.666667 |
| 456 | Jeff Withey | Utah Jazz | C | 7-0 | 231.0 | 947276.0 | 78939.666667 |
| 457 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
458 rows × 7 columns
drop_duplicates() Fonksiyonu
Veri çerçevemizde çift kayıt varsa, yani tüm veriler aynı olan birden fazla satır verisi varsa, bunlardan biri kalacak şekilde diğerlerinin silmek için drop_duplicates metodunu / fonksiyonunu kullanabiliriz.
Örnek kodları inceleyelim.
import pandas as pd
sozluk = {"isim" : ["Mustafa", "Halil", "Burak", "Emre", "Ersin", "Sertaç", "Furkan","Murat","Ahmet","Abdülkadir", "Halil", "Ersin"],
"yaş" : [25, 42, 43, 23, 37, 52, 30, 38, 40, 38, 42, 37],
"iş-meslek" : ["mühendis", "programcı", "akademisyen", "yönetici","amir","mühendis", "yönetici","müdür","veteriner","yönetici", "programcı", "amir"]}
veri = pd.DataFrame(sozluk)
print(veri)
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | mühendis |
| 1 | Halil | 42 | programcı |
| 2 | Burak | 43 | akademisyen |
| 3 | Emre | 23 | yönetici |
| 4 | Ersin | 37 | amir |
| 5 | Sertaç | 52 | mühendis |
| 6 | Furkan | 30 | yönetici |
| 7 | Murat | 38 | müdür |
| 8 | Ahmet | 40 | veteriner |
| 9 | Abdülkadir | 38 | yönetici |
| 10 | Halil | 42 | programcı |
| 11 | Ersin | 37 | amir |
Veri çerçevemizi incelediğimizde 1. ve 10. indeksli satırlardaki ile 4. ve 11. indeksli satırlardaki verilerin aynı olduğunu görüyoruz. Bu fazla verilerden kurtulalım.
print(veri.drop_duplicates())
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | mühendis |
| 1 | Halil | 42 | programcı |
| 2 | Burak | 43 | akademisyen |
| 3 | Emre | 23 | yönetici |
| 4 | Ersin | 37 | amir |
| 5 | Sertaç | 52 | mühendis |
| 6 | Furkan | 30 | yönetici |
| 7 | Murat | 38 | müdür |
| 8 | Ahmet | 40 | veteriner |
| 9 | Abdülkadir | 38 | yönetici |
Veri çerçevesinde, tüm satır verisi aynı olmasa da, sadece belirtilen sütunda aynı değere sahip verilerden birinin kalıp diğerlerinin silinmesini istersek kullanmamız gereken parametre, subset'tir.
subset Parametresi
subset parametresine sütun ismi ya da isimleri yazarken liste veri tipinde girşi yapmak gerekir, yani sütun isimlerini köşeli parantez içerisinde yazmalıyız.
import pandas as pd
sozluk = {"isim" : ["Mustafa", "Halil", "Burak", "Emre", "Ersin", "Sertaç", "Furkan","Murat","Ahmet","Abdülkadir"],
"yaş" : [25, 42, 43, 23, 37, 52, 30, 25, 40, 38],
"iş-meslek" : ["mühendis", "programcı", "akademisyen", "yönetici","amir","mühendis", "yönetici","müdür","veteriner","yönetici"]}
veri = pd.DataFrame(sozluk)
print(veri)
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | mühendis |
| 1 | Halil | 42 | programcı |
| 2 | Burak | 43 | akademisyen |
| 3 | Emre | 23 | yönetici |
| 4 | Ersin | 37 | amir |
| 5 | Sertaç | 52 | mühendis |
| 6 | Furkan | 30 | yönetici |
| 7 | Murat | 25 | müdür |
| 8 | Ahmet | 40 | veteriner |
| 9 | Abdülkadir | 38 | yönetici |
Görüldüğü üzre, veri çerçevemizde birebir aynı satır verileri bulunmuyor ancak aynı meslek grubuna sahip kayıtlar mecvut. Diyelim ki her meslek grubundan bir kişi kalacak, diğer veriler silinecek şekilde bir işlem yapmak istiyoruz. Bu durumda aşağıdaki kdu alıştırmamız gerekir.
print(veri.drop_duplicates(subset=["iş-meslek"]))
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | mühendis |
| 1 | Halil | 42 | programcı |
| 2 | Burak | 43 | akademisyen |
| 3 | Emre | 23 | yönetici |
| 4 | Ersin | 37 | amir |
| 7 | Murat | 25 | müdür |
| 8 | Ahmet | 40 | veteriner |
İndeks verilerine bakarsanız, 5. , 6. ve 9. satırlardaki verilerin silindiğini göreceksiniz. Bunun sebebi, 5. satırda iş-meslek sütununda yazan ifadenin, daha üst satırlarda var olması sebebiyle silinmesidir.
Çift olan verilerden İlki mi? sonuncu mu kalacak, hangisinin silineceğine pandas nasıl karar verecek derseniz, onun için de keep parametresini kullanmamız gerekecek.
keep Parametresi
keep parametresine last değeri atanırsa, bu kez çift verilerden sonuncusu kalacak ve ilk veriler silinecektir.
Örnek kodu inceleyelim.
print(veri.drop_duplicates(subset=["iş-meslek"], keep="last"))
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 1 | Halil | 42 | programcı |
| 2 | Burak | 43 | akademisyen |
| 4 | Ersin | 37 | amir |
| 5 | Sertaç | 52 | mühendis |
| 7 | Murat | 25 | müdür |
| 8 | Ahmet | 40 | veteriner |
| 9 | Abdülkadir | 38 | yönetici |
Görüldüğü gibi, bu kez "iş-meslek" sütununda ilk veriler olan 0. , 3. ve 6. satırlar silindi.
String Metotları
Python ile kodlama yaparken, metinsel ifadelerle uğraştığımızda kullandığımız string metotlarını hatırlarsınız. Örneğin, Metinlerin tümünü büyük harfe ya da küçük harfe çevirmek. Bu tür string metotları Pandas ile kulanmak ve veri çerçevesine uygulamak mümkün. Bunun için str ifadesini kullanabiliriz.
Önce Bir Veri Çerçevesi oluşturalım ve gözatalım.
sozluk = {"isim" : ["Mustafa", "Halil", "Burak", "Emre", "Ersin", "Sertaç", "Furkan","Murat","Ahmet","Abdülkadir"],
"yaş" : [25, 38, 41, 23, 37, 52, 30, 23, 40, 38],
"iş-meslek" : ["mühendis", "programcı", "akademisyen", "yönetici","amir","mühendis", "yönetici","müdür","veteriner","yönetici"]}
veri = pd.DataFrame(sozluk)
print(veri)
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | mühendis |
| 1 | Halil | 38 | programcı |
| 2 | Burak | 41 | akademisyen |
| 3 | Emre | 23 | yönetici |
| 4 | Ersin | 37 | amir |
| 5 | Sertaç | 52 | mühendis |
| 6 | Furkan | 30 | yönetici |
| 7 | Murat | 23 | müdür |
| 8 | Ahmet | 40 | veteriner |
| 9 | Abdülkadir | 38 | yönetici |
Veri Çerçevemizin iş-meslek sütunundaki tüm metinleri büyük harfe çevirip ekrana yazdıralım.
print(veri["iş-meslek"].str.upper())
0 MÜHENDIS
1 PROGRAMCI
2 AKADEMISYEN
3 YÖNETICI
4 AMIR
5 MÜHENDIS
6 YÖNETICI
7 MÜDÜR
8 VETERINER
9 YÖNETICI
Name: iş-meslek, dtype: object
Uyguladığımız metot sonrası, veri çerçevemizi tekrar çağırdığımızda, iş-meslek sütunundaki metinlerin değişmediğini, eski halinde kaldığını göreceğiz. Bunu sebebi, yaptığımız değişikliği bir değişken olarak alıp, iş-meslek sütununa atamamaktır. İfade etmeye çalıştığım şeyin, aşağıdaki satırda daha net anlaşılacağını düşünüyorum. Atama işlem sonrası Veri çerçevemizi çağırıp değişikiğin uygulandığını görüyoruz.
veri["iş-meslek"] = veri["iş-meslek"].str.upper()
print(veri)
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | MÜHENDIS |
| 1 | Halil | 38 | PROGRAMCI |
| 2 | Burak | 41 | AKADEMISYEN |
| 3 | Emre | 23 | YÖNETICI |
| 4 | Ersin | 37 | AMIR |
| 5 | Sertaç | 52 | MÜHENDIS |
| 6 | Furkan | 30 | YÖNETICI |
| 7 | Murat | 23 | MÜDÜR |
| 8 | Ahmet | 40 | VETERINER |
| 9 | Abdülkadir | 38 | YÖNETICI |
Şimdi de iş-meslek Sütunundaki verilerin sadece baş harflerini büyük yapalım.
veri["iş-meslek"] = veri["iş-meslek"].str.capitalize()
print(veri)
| isim | yaş | iş-meslek | |
|---|---|---|---|
| 0 | Mustafa | 25 | Mühendis |
| 1 | Halil | 38 | Programci |
| 2 | Burak | 41 | Akademisyen |
| 3 | Emre | 23 | Yönetici |
| 4 | Ersin | 37 | Amir |
| 5 | Sertaç | 52 | Mühendis |
| 6 | Furkan | 30 | Yönetici |
| 7 | Murat | 23 | Müdür |
| 8 | Ahmet | 40 | Veteriner |
| 9 | Abdülkadir | 38 | Yönetici |
Son olarak ta, veri çerçevemizim sütun başlıklarını büyük karfe çevirelim.
veri.columns = veri.columns.str.upper()
print(veri)
| ISIM | YAŞ | IŞ-MESLEK | |
|---|---|---|---|
| 0 | Mustafa | 25 | Mühendis |
| 1 | Halil | 38 | Programci |
| 2 | Burak | 41 | Akademisyen |
| 3 | Emre | 23 | Yönetici |
| 4 | Ersin | 37 | Amir |
| 5 | Sertaç | 52 | Mühendis |
| 6 | Furkan | 30 | Yönetici |
| 7 | Murat | 23 | Müdür |
| 8 | Ahmet | 40 | Veteriner |
| 9 | Abdülkadir | 38 | Yönetici |
transpose() Fonksiyonu
Satırların sütuna, sütunların satıra çevrilme işlemini transpose() fonksiyonu yardımıyla gerçekleştirebiliriz. Bu fonksiyon, Excel, LibreOfis,...vb uygulamalarda, "İşlemi tersine çevir" komutu ile aynı sonucu verir. Yukarıda oluşturduğumuz veri çerçevemizin transpozunu aşağıdaki şekilde alabiliriz.
print(veri.transpose())
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| isim | Mustafa | Halil | Burak | Emre | Ersin | Sertaç | Furkan | Murat | Ahmet | Abdülkadir |
| yaş | 25 | 38 | 41 | 23 | 37 | 52 | 30 | 23 | 40 | 38 |
| iş-meslek | mühendis | programcı | akademisyen | yönetici | amir | mühendis | yönetici | müdür | veteriner | yönetici |
apply() Fonksiyonu
Python programlama dilini öğrenirken karşılaştığımız fonksiyonlar konusunu hatırlarsınız Kullanıcı tarafından yazılan ya da standart python fonksiyonlarını, veri çerçevemize uygulamak istersek, apply() fonksiyonu kullanmamız gerekir.
Yukarıdaki iş-meslek sütunundaki metinlerin büyük harfe dönüştürülmesi örneğini, bir de apply() fonksiyonu ile uygulayalım.
def buyuk_harf(x):
return x.upper()
print(veri["IŞ-MESLEK"].apply(buyuk_harf))
0 MÜHENDIS
1 PROGRAMCI
2 AKADEMISYEN
3 YÖNETICI
4 AMIR
5 MÜHENDIS
6 YÖNETICI
7 MÜDÜR
8 VETERINER
9 YÖNETICI
Name: IŞ-MESLEK, dtype: object
İşlemin kalıcı olmsı için yine atama operatörünü kullanmalıyız.
veri["IŞ-MESLEK"] = veri["IŞ-MESLEK"].apply(buyuk_harf)
print(veri)
| ISIM | YAŞ | IŞ-MESLEK | |
|---|---|---|---|
| 0 | Mustafa | 25 | MÜHENDIS |
| 1 | Halil | 38 | PROGRAMCI |
| 2 | Burak | 41 | AKADEMISYEN |
| 3 | Emre | 23 | YÖNETICI |
| 4 | Ersin | 37 | AMIR |
| 5 | Sertaç | 52 | MÜHENDIS |
| 6 | Furkan | 30 | YÖNETICI |
| 7 | Murat | 23 | MÜDÜR |
| 8 | Ahmet | 40 | VETERINER |
| 9 | Abdülkadir | 38 | YÖNETICI |
Veri Çerçevelerini Birleştir
Pandas Kütüphanesinde Veri çerçevelerini birleştirmek için kullanılabilecek birden fazla Fonksiyon/Metot vardır. Aşağıda bu Fonksiyonların kullanımı anlatılmıştır.
concat() Fonksiyonu
Concat kelimesi Concatenate kelimesinin kısaltamasıdır. Concatenate kelimesinin Türkçe karşılığı Birleştir'dir.
concat() fonksiyonu ile veri çerçeveleri alt alta ya da yan yana birleştirilebilir. Varsayılan değer satır bazlı yani alt alta birleştirmedir.
Birleştirme örneklerini öğrenemek için öncelikle 2 sözlük yapısı oluşturup, bunları veri çerçevesine dönüştürelim.
veri1 = {'A': ['A1','A2','A3','A4'],'B': ['B1','B2','B3','B4'],'C': ['C1','C2','C3','C4']}
veri2 = {'A': ['A5','A6','A7','A8'],'B': ['B5','B6','B7','B8'],'C': ['C5','C6','C7','C8']}
df1 = pd.DataFrame(veri1, index = [1,2,3,4])
df2 = pd.DataFrame(veri2, index = [5,6,7,8])
print(df1)
| A | B | C | |
|---|---|---|---|
| 1 | A1 | B1 | C1 |
| 2 | A2 | B2 | C2 |
| 3 | A3 | B3 | C3 |
| 4 | A4 | B4 | C4 |
print(df2)
| A | B | C | |
|---|---|---|---|
| 5 | A5 | B5 | C5 |
| 6 | A6 | B6 | C6 |
| 7 | A7 | B7 | C7 |
| 8 | A8 | B8 | C8 |
Oluşturduğumuz veri çerçevelerini, concat() fonksiyonu ile birleştirelim. concat() fonksiyonuna en az iki adet veri çevçevesi eklemek gerekir. Malumunuz, Pandas'ta genellikle birden fazla parametre, seçenek ekleneceği zaman, bu değerler köşeli parantez içerisinde yani liste veri tipi olarak yazılır.
print(pd.concat([df1, df2]))
| A | B | C | |
|---|---|---|---|
| 1 | A1 | B1 | C1 |
| 2 | A2 | B2 | C2 |
| 3 | A3 | B3 | C3 |
| 4 | A4 | B4 | C4 |
| 5 | A5 | B5 | C5 |
| 6 | A6 | B6 | C6 |
| 7 | A7 | B7 | C7 |
| 8 | A8 | B8 | C8 |
Gördüğünüz gibi, iki veri çerçevesi altalta birleştirildi.
axis parametresi
Hatırlarsanız drop metodunu anlatırken axis parametresinden bahsetmiştik. axis parametresi, 0 ve 1 değerlerini alır, 0 satırları, 1 ise sütunları temsil eder demiştik. Aynı parametreyi birleştirme işleminde de kullanabiliriz. eğer axis parametresi kullanılmaz ise, varsayılan değer axis = 0 olduğu için yani satırları baz alarak birleştirme yapılır.
Şimdi axis=1 parametresini ekleyerek veri çerçevelerini yanyana birleştirmeyi deneyelim.
print(pd.concat([df1, df2], axis = 1))
| A | B | C | A | B | C | |
|---|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | NaN | NaN | NaN |
| 2 | A2 | B2 | C2 | NaN | NaN | NaN |
| 3 | A3 | B3 | C3 | NaN | NaN | NaN |
| 4 | A4 | B4 | C4 | NaN | NaN | NaN |
| 5 | NaN | NaN | NaN | A5 | B5 | C5 |
| 6 | NaN | NaN | NaN | A6 | B6 | C6 |
| 7 | NaN | NaN | NaN | A7 | B7 | C7 |
| 8 | NaN | NaN | NaN | A8 | B8 | C8 |
Bu durumda, 2 veri çerçevesi yanyana birleştirildi ancak veri çerçevelerinde aynı indeks değerleri bulunmadığı için ilgili indeks değerinin krşılığında NaN (Not A Number) değeri atandı.
Eğer aşağıdaki gibi bir veri çerçevemiz olsaydı ve bu veri çerçevesini df1 ile yanyana birleştirseydik nasıl bir sonuç elde ederdik dersiniz.
veri3 = {'A': ['A5','A6','A7','A8'],'B': ['B5','B6','B7','B8'],'C': ['C5','C6','C7','C8']}
df3 = pd.DataFrame(veri3, index = [1,6,3,8])
print(df3)
| A | B | C | |
|---|---|---|---|
| 1 | A5 | B5 | C5 |
| 6 | A6 | B6 | C6 |
| 3 | A7 | B7 | C7 |
| 8 | A8 | B8 | C8 |
print(pd.concat([df1, df3], axis = 1))
| A | B | C | A | B | C | |
|---|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | A5 | B5 | C5 |
| 2 | A2 | B2 | C2 | NaN | NaN | NaN |
| 3 | A3 | B3 | C3 | A7 | B7 | C7 |
| 4 | A4 | B4 | C4 | NaN | NaN | NaN |
| 6 | NaN | NaN | NaN | A6 | B6 | C6 |
| 8 | NaN | NaN | NaN | A8 | B8 | C8 |
df1 ve df3'te ortak indeks değerleri olduğu için 1. ve 3. satırlar tamamen geçerli veri ile doldu.
concat fonksiyonu sadece 2 veri çerçevesini birleştirmiyor. 2'den fazla veri çerçevesini de birleştiriyor. Oluşturduğumuz df1, df2 ve df3 veri çerçevelerini altalta ve yanyana birleştirip sonuçları inceleyelim.
print(pd.concat([df1, df2, df3]))
| A | B | C | |
|---|---|---|---|
| 1 | A1 | B1 | C1 |
| 2 | A2 | B2 | C2 |
| 3 | A3 | B3 | C3 |
| 4 | A4 | B4 | C4 |
| 5 | A5 | B5 | C5 |
| 6 | A6 | B6 | C6 |
| 7 | A7 | B7 | C7 |
| 8 | A8 | B8 | C8 |
| 1 | A5 | B5 | C5 |
| 6 | A6 | B6 | C6 |
| 3 | A7 | B7 | C7 |
| 8 | A8 | B8 | C8 |
print(pd.concat([df1, df2, df3], axis = 1))
| A | B | C | A | B | C | A | B | C | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | NaN | NaN | NaN | A5 | B5 | C5 |
| 2 | A2 | B2 | C2 | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | A3 | B3 | C3 | NaN | NaN | NaN | A7 | B7 | C7 |
| 4 | A4 | B4 | C4 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | NaN | NaN | NaN | A5 | B5 | C5 | NaN | NaN | NaN |
| 6 | NaN | NaN | NaN | A6 | B6 | C6 | A6 | B6 | C6 |
| 7 | NaN | NaN | NaN | A7 | B7 | C7 | NaN | NaN | NaN |
| 8 | NaN | NaN | NaN | A8 | B8 | C8 | A8 | B8 | C8 |
join() Fonksiyonu
join() metodu, Veri çerçevelerini birleştirmek için kullanılan fonksiyonlardan biridir. join() fonksiyonunun parametreleri kullanılarak, matematik dersinteki Kümeler konusu mantığında birleştirme işlemleri yapılabilir.
join() metodu, parametresiz kullanıldığında varsayılan olarak left join (how = "left")
değerini alır. Sol tarafta yazılan veri çerçevesindeki tüm değerler alınır, bu çerçevedeki indeks değerleri sağ tarafta yazılan veri çerçevesinde varsa, bu değerlere birleştirilir. Soldaki indeks değeri sağdaki veri çerçeveside yoksa o halde ilgili satır ve sütunlara eksik veri mahiyetinde NaN (Not a Number) değeri atanır.
veri4 = {'Ad': ["mustafa", "halil", "emre", "burak"],
'yas': [38,42,35,44],
'meslek': ["yönetici", "mak.müh.", "yönetici", "akademisyen"]}
df4 = pd.DataFrame(veri4)
print(df4)
| Ad | yas | meslek | |
|---|---|---|---|
| 0 | mustafa | 38 | yönetici |
| 1 | halil | 42 | mak.müh. |
| 2 | emre | 35 | yönetici |
| 3 | burak | 44 | akademisyen |
print(df1.join(df4))
| A | B | C | Ad | yas | meslek | |
|---|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | halil | 42.0 | mak.müh. |
| 2 | A2 | B2 | C2 | emre | 35.0 | yönetici |
| 3 | A3 | B3 | C3 | burak | 44.0 | akademisyen |
| 4 | A4 | B4 | C4 | NaN | NaN | NaN |
Sonuca bakarsanız, df1 veri çerçevesinin temel alındı ve df4'teki indeks değerlerine bakılarak, df1'in indeks değeri olan sütunlarının veri çerçevesine dahil edildiğini, katıldığını görebilirsiniz. Yani ilk veri çerçevesine ilave olarak, iki veri çerçevesinin ortak indeksleri eklenmiş diyebiliriz. İşlemin tersini yaparsak, yani df4'ü temel alarak join metodunu uygularsak ne olur?
print(df4.join(df1))
| Ad | yas | meslek | A | B | C | |
|---|---|---|---|---|---|---|
| 0 | mustafa | 38 | yönetici | NaN | NaN | NaN |
| 1 | halil | 42 | mak.müh. | A1 | B1 | C1 |
| 2 | emre | 35 | yönetici | A2 | B2 | C2 |
| 3 | burak | 44 | akademisyen | A3 | B3 | C3 |
Bu kez de, tahmin ettiğimiz gibi, df4 veri çerçevesi temel alındı, ve df1'in ortak indeks değerleri dahil edildi, df4'ün indeks değeri df1 de olmadığı durumda, ilgili satıra NaN değeri atandı.
how parametresi
join metodunun how parametresi ile, veri çerçevelerinin, sağdaki ya da soldaki veri çerçevesine göre katılma/dahil edilme seçeneğini ayarlayabilir, veri çerçevelerinin birleşimini ya da kesişimini de alabiliriz. how parametresi, left, right, inner ve outer değerlerini alır. Varsayılan değer left'tir. (left join)
Aşağıdaki örneği inceleyerek konuyu daha iyi anlayabilirsiniz.
how parametresinin seçenekleri
join() Fonksiyonunun how parametresinin alabileceği seçenekler;
left(varsayılan)rightouterinner
Şimdi bu seçenekleri sıra ile inceleyelim.
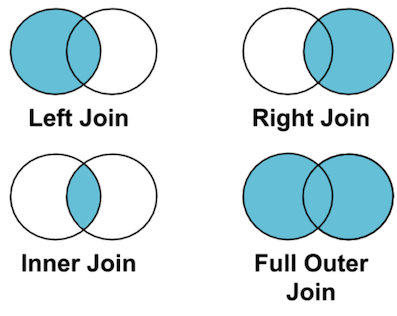
left join
join() metodunun, how parametresi almadan kullanıldığında varsayılan olarak left join (how = "left") değerini aldığından bahsetmiştik. Bu durumda Sol tarafta yazılan veri çerçevesindeki tüm değerler alınır, bu çerçevedeki indeks değerleri sağ tarafta yazılan veri çerçevesinde varsa, bu değerlere birleştirilir. Soldaki indeks değeri sağdaki veri çerçeveside yoksa o halde ilgili satır ve sütunlara eksik veri mahiyetinde NaN (Not a Number) değeri atanır.
how = "left" kodunu eklesek te eklemesekte aynı sonucu elde ederiz. Ağaşıdaki kodları ayrı ayrı çalıştırıp, göreabilirsiniz.
print(df1.join(df4))
print(df1.join(df4, how="left"))
| A | B | C | Ad | yas | meslek | |
|---|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | halil | 42.0 | mak.müh. |
| 2 | A2 | B2 | C2 | emre | 35.0 | yönetici |
| 3 | A3 | B3 | C3 | burak | 44.0 | akademisyen |
| 4 | A4 | B4 | C4 | NaN | NaN | NaN |
right join
Aynı kodu, how="right" parametresi ekleyerek te çalıştırıp sonucu görelim.
print(df1.join(df4, how="right"))
| A | B | C | Ad | yas | meslek | |
|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | mustafa | 38 | yönetici |
| 1 | A1 | B1 | C1 | halil | 42 | mak.müh. |
| 2 | A2 | B2 | C2 | emre | 35 | yönetici |
| 3 | A3 | B3 | C3 | burak | 44 | akademisyen |
how parametresi eklenmeyen İlk kodda, indeksler 1'den yani df1 temel alınarak birleştirme işlemi gerçekleştirilirken, how="right" parametresi eklenen ikinci kodda df2 yani sağdaki veri çerçevesi temel alınarak (indeks değerli 0'dan başlayarak) birleştirme işlemi gerçekleşti.
outer join
outerseçeneği kullanıldığında, Birleşik küme mantığı ile birleştirme işlemi gerçekleşir. Her iki veri çerçevesi tüm içeriği ile alınıp, yanyana birleştirilir.
print(df1.join(df4, how="outer"))
| A | B | C | Ad | yas | meslek | |
|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | mustafa | 38.0 | yönetici |
| 1 | A1 | B1 | C1 | halil | 42.0 | mak.müh. |
| 2 | A2 | B2 | C2 | emre | 35.0 | yönetici |
| 3 | A3 | B3 | C3 | burak | 44.0 | akademisyen |
| 4 | A4 | B4 | C4 | NaN | NaN | NaN |
Görüldüğü üzre, önce df1 veri çerçevesi alındı, daha sonra df4 veri çerçevesinin içeriği alınarak yanına dahil edildi. Her iki ver içerçevesinde indeks değerleri içermeyen satırlan NaN olarak belirlendi.
inner join
innerseçeneği kullanıldığında, Kesişim kümesi mantığı ile birleştirme işlemi gerçekleşir. İki veri çerçevesinde ortak indeks değerlerine sahip satırlar alınır, yanyana birleştirilir.
df1 1'den 4'e kadar olan indeks değerlerine sahipken, df4 0'dan 3'e kadar indeks değerlerine sahip veri çerçeveleridir. Şimdi bu iki veri çerçevesini how="inner" parametresi ile birbirine dahil etmek istersen ne olur?
print(df1.join(df4, how="inner"))
| A | B | C | Ad | yas | meslek | |
|---|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | halil | 42 | mak.müh. |
| 2 | A2 | B2 | C2 | emre | 35 | yönetici |
| 3 | A3 | B3 | C3 | burak | 44 | akademisyen |
İkisinde de ortak olan 1,2 ve 3 nolu indeks değerlerindeki veriler birleştirildi yani her iki veri çerçevesinin kesişimi alındı.
print(df4.join(df1, sort= True))
| Ad | yas | meslek | A | B | C | |
|---|---|---|---|---|---|---|
| 0 | mustafa | 38 | yönetici | NaN | NaN | NaN |
| 1 | halil | 42 | mak.müh. | A1 | B1 | C1 |
| 2 | emre | 35 | yönetici | A2 | B2 | C2 |
| 3 | burak | 44 | akademisyen | A3 | B3 | C3 |
merge() Fonksiyonu
merge() fonksiyonu join() fonksiyonuna benzer ancak bazı farklı özellikleri vardır. Veri Çerçevesi (DataFrame) veya adlandırılmış Seri nesnelerini (Series) veritabanı stili birleştirme yöntemi ile (SQL’de bulunan inner join, outer join … ‘e benzer) birleştirmek için merge() fonksiyonunu kullanılabilir.
Adlandırılmış Seri nesnesi (Series), adlandırılmış tek bir sütuna sahip Veri çerçevesi (DataFrame) olarak ele alınır.
merge() fonksiyonunun bir çok parametresi vardır. Biz burada temel bir kaç parametreye değineceğiz.
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
on Parametresi
on parametresi, Veri Çerçevelerinin hangi sütun baz alınarak birleştirileceğini belirteceğimiz parametredir. Öğrenci isimleri ile Vize ve Final sonuçlarının bulunduğu iki veri çerçevesi oluşturup, parametrelerin kullanımını görelim.
import pandas as pd
vize = pd.DataFrame({"Ogrenci": ["ali", "busra", "ceyhun", "eda", "gamze", "kamil"],
"Sinav Sonucu": [41, 58, 73, 81, 95, 85]})
final = pd.DataFrame({"Ogrenci": ["ali", "busra", "derya", "fatih", "halil"],
"Sinav Sonucu": [60, 68, 74, 90, 95]})
print(vize)
| Ogrenci | Sinav Sonucu | |
|---|---|---|
| 0 | ali | 41 |
| 1 | busra | 58 |
| 2 | ceyhun | 73 |
| 3 | eda | 81 |
| 4 | gamze | 95 |
| 5 | kamil | 85 |
print(final)
| Ogrenci | Sinav Sonucu | |
|---|---|---|
| 0 | ali | 60 |
| 1 | busra | 68 |
| 2 | derya | 74 |
| 3 | fatih | 90 |
| 4 | halil | 95 |
Yukarıdaki iki veri çerçevesini, Ogrenci isimli sütunu temel alarak birleştirlim. how parametresine takılmayın, aşağıda detaylıca anlatılıyor.
tumu = pd.merge(vize, final, on = "Ogrenci", how = "outer")
print(tumu)
| Ogrenci | Sinav Sonucu_x | Sinav Sonucu_y | |
|---|---|---|---|
| 0 | ali | 41.0 | 60.0 |
| 1 | busra | 58.0 | 68.0 |
| 2 | ceyhun | 73.0 | NaN |
| 3 | eda | 81.0 | NaN |
| 4 | gamze | 95.0 | NaN |
| 5 | kamil | 85.0 | NaN |
| 6 | derya | NaN | 74.0 |
| 7 | fatih | NaN | 90.0 |
| 8 | halil | NaN | 95.0 |
Birleştirme işlemi sonucunda, İki veri çerçevesindeki tüm veriler, yeni veri çerçevesinde birleştirildi. Hem Vize hemde Final veri çerçevelerinde isimleri bulunan öğrencilerin sınav sonuçları yeni veri çerçevesinde eklenmişken, vize ya da final sonucu olmayan öğrenciler için, ilgili sütun değerleri NaN (Not a Number) olarak ayarlandı.
how Parametresi
how parametresi, veri çerçevelerini birleştirirken matematikteki Kümeler konusuna benzer seçenekler sunar. merge() fonksiyonunda how parametresi kullanılmadığı taktirde varsayılan olarak inner seçeneği belirtilmiş olur ve birleştirilecek veri çerçevelerinin sadece ortak değerleri alınarak (ortak küme gibi davranarak) birleştirme
işlemi gerçekleştirilir.
Birleştirme işlemi sonucunda Sütun başlıklarının sonuna varsayılan _x ve _y sonekleri eklenir.
how Parametresi için kullanılabilecek seçenekler:
inner(varsayılan)outerleftrightcross
inner Seçeneği
inner seçeneği, sadece iki veri çerçevesinde de bulunan ortak değerleri birleştirir. Tek veri çerçevesinde olan değerler silinir. how = "inner" ibaresini yazsak ta yazmasak ta aynı sonucu elde ederiz. Aşağıdaki İki kod, aynı sonucu verir, deneyip görelim.
print(pd.merge(vize, final, on = "Ogrenci", how = "inner"))
| Ogrenci | Sinav Sonucu_x | Sinav Sonucu_y | |
|---|---|---|---|
| 0 | ali | 41 | 60 |
| 1 | busra | 58 | 68 |
print(pd.merge(vize, final, on = "Ogrenci"))
| Ogrenci | Sinav Sonucu_x | Sinav Sonucu_y | |
|---|---|---|---|
| 0 | ali | 41 | 60 |
| 1 | busra | 58 | 68 |
outer Seçeneği
outer seçeneği kullanıldığında, iki veri çerçevesinde bulunan tüm değerler birleştirilir. Sol tarafta yazılan veri çerçevesindeki değerler temel alınır. İki veri çerçevesinde bulunan ortak değerler korunur, aksi halde eksik değerler için NaN değeri atanır.
print(pd.merge(vize, final, on = "Ogrenci", how = "outer"))
| Ogrenci | Sinav Sonucu_x | Sinav Sonucu_y | |
|---|---|---|---|
| 0 | ali | 41.0 | 60.0 |
| 1 | busra | 58.0 | 68.0 |
| 2 | ceyhun | 73.0 | NaN |
| 3 | eda | 81.0 | NaN |
| 4 | gamze | 95.0 | NaN |
| 5 | kamil | 85.0 | NaN |
| 6 | derya | NaN | 74.0 |
| 7 | fatih | NaN | 90.0 |
| 8 | halil | NaN | 95.0 |
left Seçeneği
left seçeneği ile yapılan birleştirme işleminde, sol tarafta yazılan veri çerçevesinin tüm değerlerini alır ve sağ tarafta yazılan veri çerçevesindeki ortak değerleri tabloya ekler. Solda yazılan veri çerçevesindeki değerlerin, sağda yazılan veri çerçevesinde karşılığı yoksa, ilgili sütuna NaN değeri atanır. Sağ tarafta yazılan veri çerçevesinin, sol tarafta yazılan veri çerçevesinde karşılığı yoksa, bu değerler yok sayılır,
birleştirme işlemine dahil edilmez.
print(pd.merge(vize, final, on = "Ogrenci", how = "left"))
| Ogrenci | Sinav Sonucu_x | Sinav Sonucu_y | |
|---|---|---|---|
| 0 | ali | 41 | 60.0 |
| 1 | busra | 58 | 68.0 |
| 2 | ceyhun | 73 | NaN |
| 3 | eda | 81 | NaN |
| 4 | gamze | 95 | NaN |
| 5 | kamil | 85 | NaN |
right Seçeneği
right seçeneği ile yapılan birleştirme işleminde, sağ tarafta yazılan veri çerçevesinin tüm değerlerini alır ve sol tarafta yazılan veri çerçevesindeki ortak değerleri tabloya ekler. Sağda yazılan veri çerçevesindeki değerlerin, solda yazılan veri çerçevesinde karşılığı yoksa, ilgili sütuna NaN değeri atanır. Sol tarafta yazılan veri çerçevesinin, sağ tarafta yazılan veri çerçevesinde karşılığı yoksa, bu değerler yok sayılır,
birleştirme işlemine dahil edilmez.
print(pd.merge(vize, final, on = "Ogrenci", how = "right"))
| Ogrenci | Sinav Sonucu_x | Sinav Sonucu_y | |
|---|---|---|---|
| 0 | ali | 41.0 | 60 |
| 1 | busra | 58.0 | 68 |
| 2 | derya | NaN | 74 |
| 3 | fatih | NaN | 90 |
| 4 | halil | NaN | 95 |
cross Seçeneği
cross seçeneği sonucunda, kartezyen çarpımı yöntemi ile birleştirme yapılır.
veri1 = pd.DataFrame({'HARF': ['A', 'B', "C"]})
veri2 = pd.DataFrame({'SAYI': [10,20,30]})
print(veri1)
| HARF | |
|---|---|
| 0 | A |
| 1 | B |
| 2 | C |
print(veri2)
| SAYI | |
|---|---|
| 0 | 10 |
| 1 | 20 |
| 2 | 30 |
print(pd.merge(veri1, veri2, how="cross"))
| HARF | SAYI | |
|---|---|---|
| 0 | A | 10 |
| 1 | A | 20 |
| 2 | A | 30 |
| 3 | B | 10 |
| 4 | B | 20 |
| 5 | B | 30 |
| 6 | C | 10 |
| 7 | C | 20 |
| 8 | C | 30 |
left_on Parametresi
Bu parametre opsiyonel yani İsteğe bağlıdır, kullanmak zorunda değilsiniz. Soldaki Veri Çerçevesi üzerinde birleştirmenin hangi düzeyde yapılacağını belirtmek için kullanılır. Sütun başlıklarının sonuna varsayılan _x ve _y sonekleri eklenir.
left_on parametresi, etiket veya liste ya da dizi benzeri veri alır.
right_on Parametresi
Bu parametre opsiyonel yani İsteğe bağlıdır, kullanmak zorunda değilsiniz. Sağdaki Veri Çerçevesi üzerinde birleştirmenin hangi düzeyde yapılacağını belirtmek için kullanılır. Sütun başlıklarının sonuna varsayılan _x ve _y sonekleri eklenir.
right_on parametresi, etiket veya liste ya da dizi benzeri veri alır.
arastirma1 = pd.DataFrame({'Manav_1': ['elma', 'nar', 'portakal', 'elma'],
'fiyat': [1, 2, 3, 4]})
arastirma2 = pd.DataFrame({'Manav_2': ['elma', 'nar', 'portakal', 'elma'],
'fiyat': [5, 6, 7, 8]})
print(arastirma1)
| Manav_1 | fiyat | |
|---|---|---|
| 0 | elma | 1 |
| 1 | nar | 2 |
| 2 | portakal | 3 |
| 3 | elma | 4 |
print(arastirma2)
| Manav_2 | fiyat | |
|---|---|---|
| 0 | elma | 5 |
| 1 | nar | 6 |
| 2 | portakal | 7 |
| 3 | elma | 8 |
print(arastirma1.merge(arastirma2, left_on='Manav_1', right_on='Manav_2'))
| Manav_1 | fiyat_x | Manav_2 | fiyat_y | |
|---|---|---|---|---|
| 0 | elma | 1 | elma | 5 |
| 1 | elma | 1 | elma | 8 |
| 2 | elma | 4 | elma | 5 |
| 3 | elma | 4 | elma | 8 |
| 4 | nar | 2 | nar | 6 |
| 5 | portakal | 3 | portakal | 7 |
print(arastirma2.merge(arastirma1, right_on='Manav_1', left_on='Manav_2'))
| Manav_2 | fiyat_x | Manav_1 | fiyat_y | |
|---|---|---|---|---|
| 0 | elma | 5 | elma | 1 |
| 1 | elma | 5 | elma | 4 |
| 2 | elma | 8 | elma | 1 |
| 3 | elma | 8 | elma | 4 |
| 4 | nar | 6 | nar | 2 |
| 5 | portakal | 7 | portakal | 3 |
suffixes Parametresi
merge() fonksiyonu ile birleştirme işlemi sonucunda, sütun başlıklarının sonuna _x ve _y soneklerinin dahil edildiğini söyledik. Bu değer vaysayılan değerdir.
Bu değeri değiştirmek ve sütun başlıklarının sonuna, istediğimiz değeri eklemek istersek bu işlemi suffixes parametresi ile yapabiliriz.
print(arastirma1.merge(arastirma2, left_on='Manav_1', right_on='Manav_2',
suffixes=("_bir", "_iki")))
| Manav_1 | fiyat_bir | Manav_2 | fiyat_iki | |
|---|---|---|---|---|
| 0 | elma | 1 | elma | 5 |
| 1 | elma | 1 | elma | 8 |
| 2 | elma | 4 | elma | 5 |
| 3 | elma | 4 | elma | 8 |
| 4 | nar | 2 | nar | 6 |
| 5 | portakal | 3 | portakal | 7 |