Cts 29 Kasım 2025
Tags:
add() Metodu
pandas.DataFrame.add metodu, bir DataFrame ile başka bir nesneyi öğe bazında (element-wise) toplamak için kullanılan ikili bir operatör sarmalayıcısıdır.
Sözdizimi:
DataFrame.add(other, axis='columns', level=None, fill_value=None)
Aşama 1: Temel Amaç ve Eşdeğerlik
-
Basit Toplama: Bu metodun temel amacı, bir DataFrame'in her bir hücresini (elementini …
Continue reading »
Cts 29 Kasım 2025
Tags:
notna() Metodu
pandas.notna() metodu, bir dizi benzeri nesne için eksik olmayan (geçerli) değerleri tespit etmek amacıyla kullanılır.
Giriş nesnesinin veya dizisinin NaN, None veya NaT (Zaman Değil) gibi tanınan eksik değerler içerip içermediğini kontrol eder. Kontrol sonucunda, geçerli olması durumunda True, eksik olması durumunda ise False değerini döndüren bir …
Continue reading »
Paz 23 Kasım 2025
Tags:
isna() Metodu
isna(), veri analizi yaparken en sık kullanılan ve en temel fonksiyonlardan biridir. Bunu bir "Kayıp Veri Dedektifi" gibi düşünebilirsin.
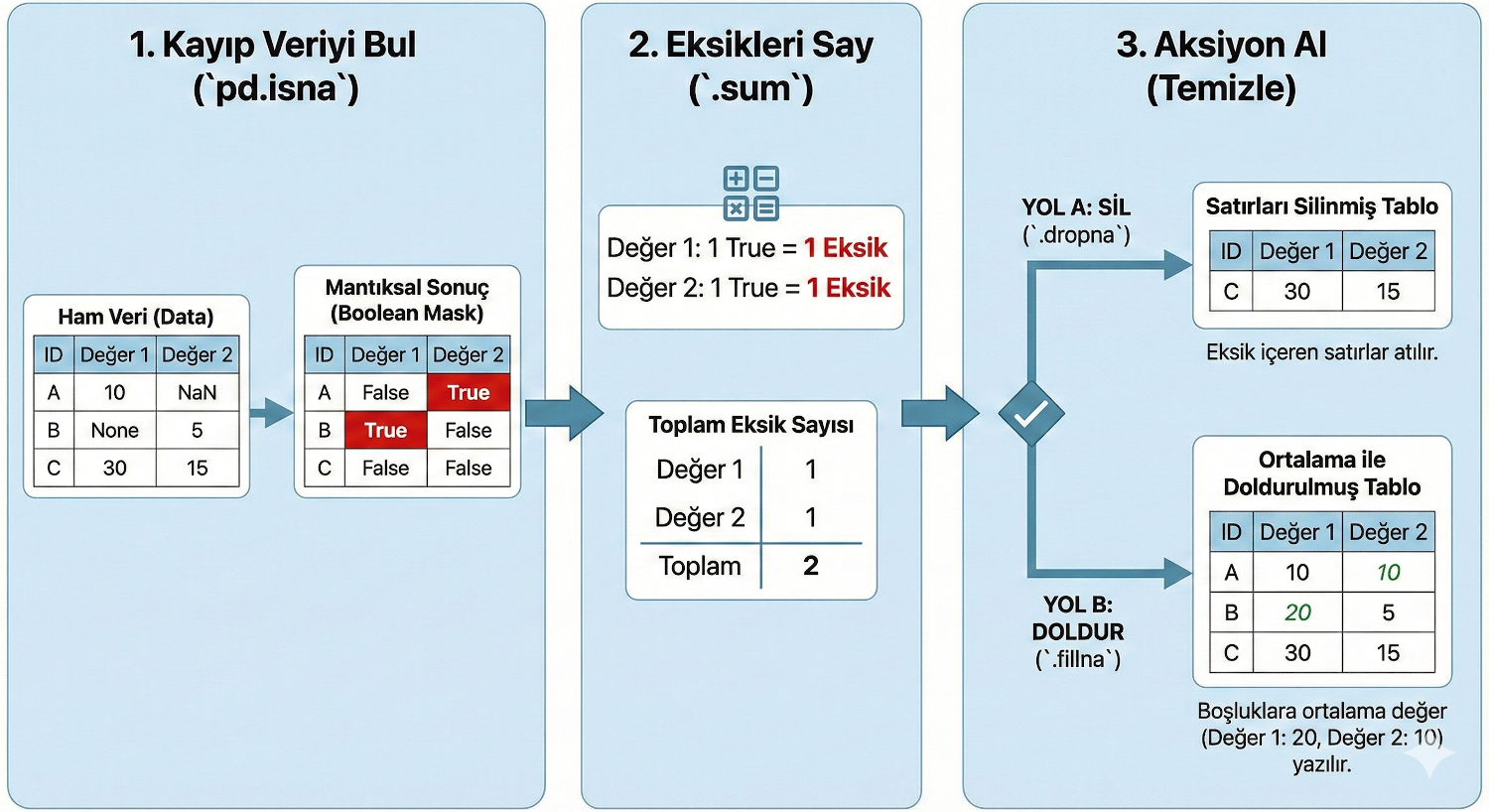
Sözdizimi:
Parametreler:
pandas.isna fonksiyonu, diğer karmaşık pandas fonksiyonlarının aksine (örneğin read_csv gibi onlarca ayarı olanların aksine) çok sade ve net bir yapıya sahiptir.
Aslında teknik …
Continue reading »
Cts 22 Kasım 2025
Tags:
replace() Metodu
Basitçe anlatmak gerekirse: replace() metodu, bir DataFrame (veri tablosu) içindeki belirli değerleri bulup, onları istediğiniz yeni değerlerle değiştirmenizi sağlar. Excel'deki "Bul ve Değiştir" (Find & Replace) özelliğinin kodla yapılan hali gibidir.
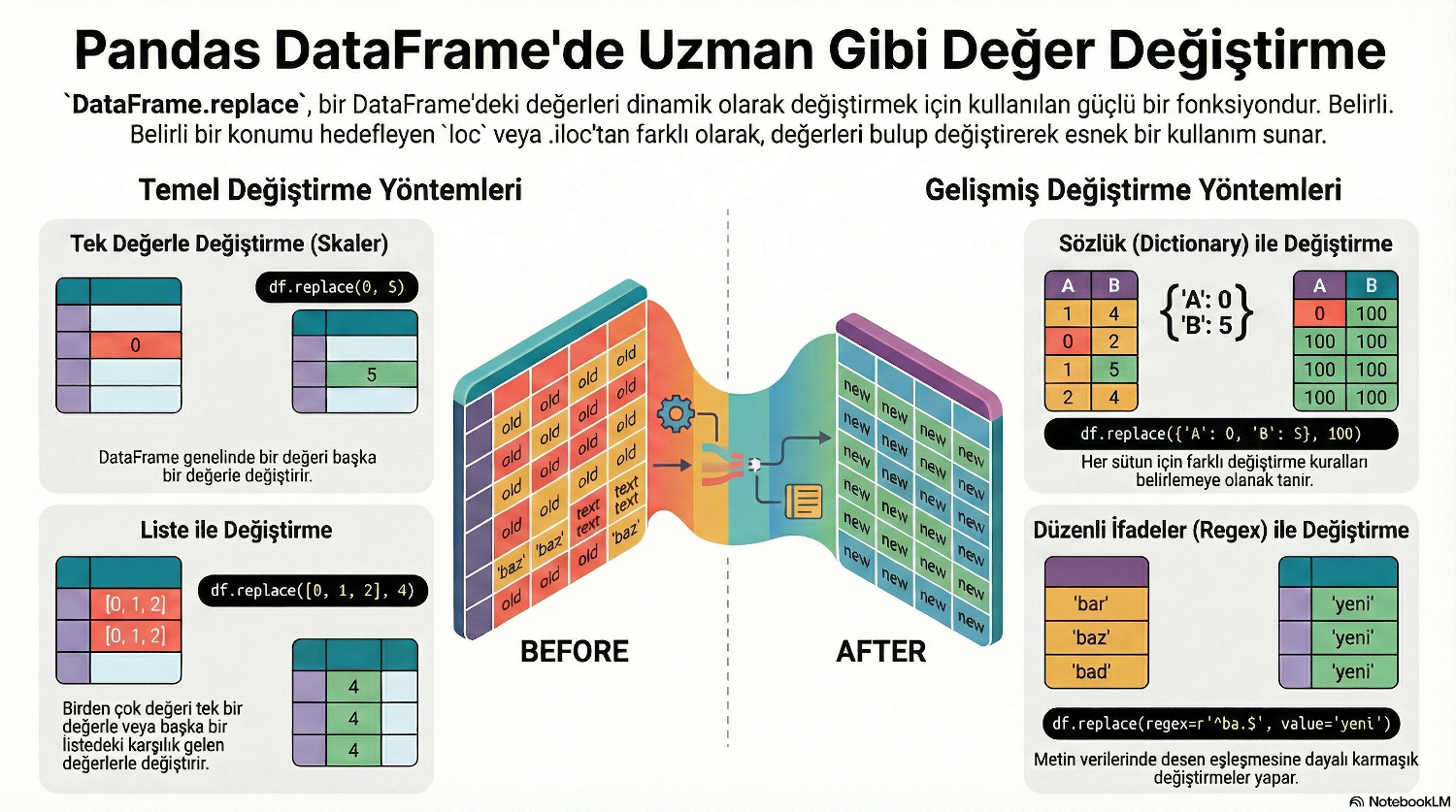
Sözdizimi:
DataFrame.replace(to_replace=None, value=<no_default>, *,
inplace=False, limit=None, regex=False,
method=<no_default>)
Parametreler:
Continue reading »
Cts 22 Kasım 2025
Tags:
convert_dtypes() Metodu
Bu metodu, veri setini otomatik olarak temizleyen ve düzenleyen "akıllı bir veri tipi (türü) dönüştürücüsü" gibi düşünebilirsin.
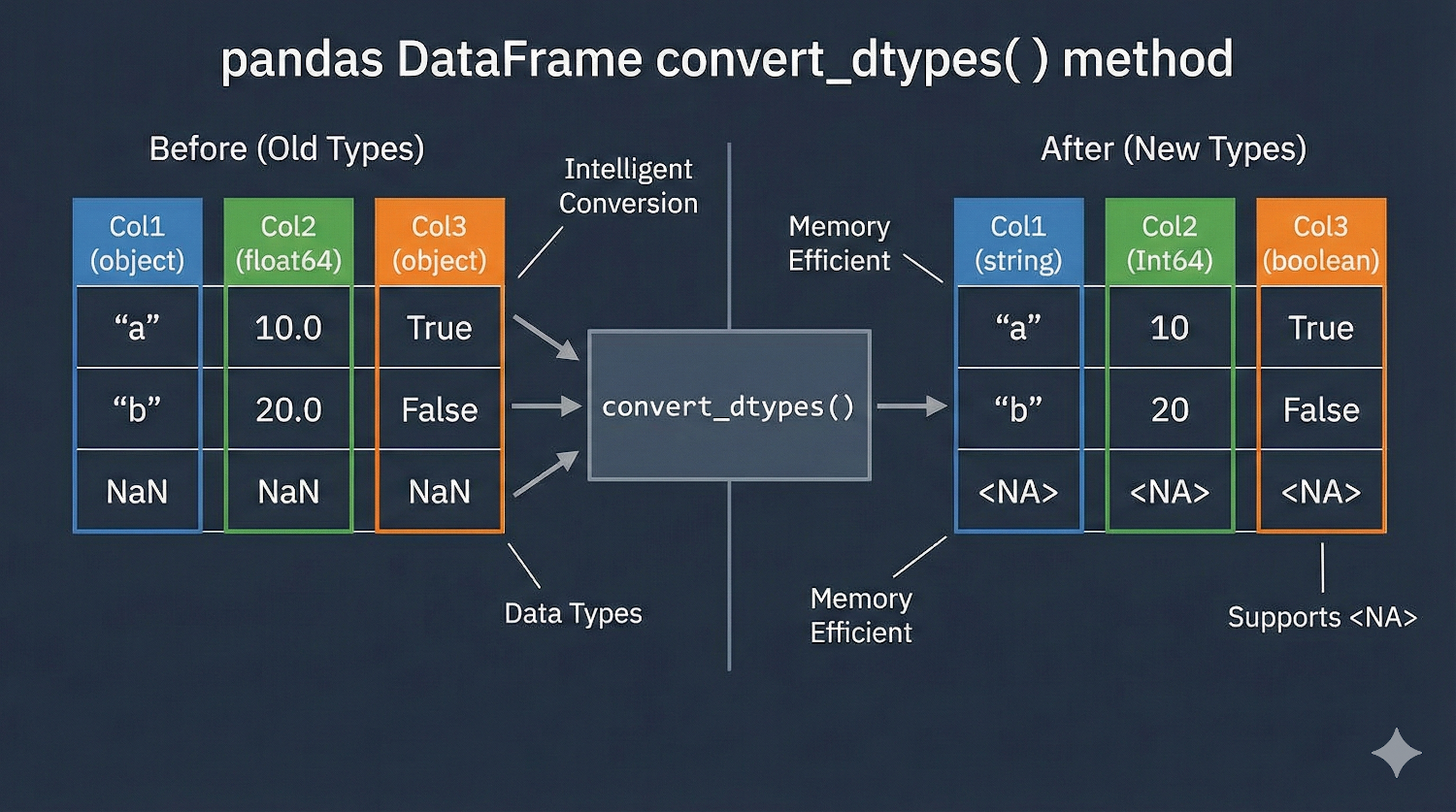
Sözdizimi:
DataFrame.convert_dtypes(infer_objects=True, convert_string=True,
convert_integer=True, convert_boolean=True,
convert_floating=True,
dtype_backend='numpy_nullable')
Temel Sorun Nedir? (Neden Buna İhtiyacımız Var?)
Pandas'ın eski sürümlerinde veya standart NumPy kullanımında şöyle can …
Continue reading »
Cts 22 Kasım 2025
Tags:
astype() Metodu
astype() metodu, Pandas'taki veri çerçevelerinin (DataFrame) veya serilerin (Series) veri tiplerini / türlerini (dtype) değiştirmek için kullanılan temel bir fonksiyondur.

astype() metodu ile bir DataFrame'deki tüm sütunları veya belirli sütunları istediğiniz bir veri tipine dönüştürebiliriz. Veri analizi sırasında, verilerin doğru şekilde işlenmesi, filtrelenmesi ve hafızada daha verimli saklanması için …
Continue reading »
Cum 21 Kasım 2025
Tags:
resample() Metodu
resample() Metodu, zaman serisi verilerinin frekansını dönüştürmek ve yeniden örneklemek için kullanılan temel bir metottur.
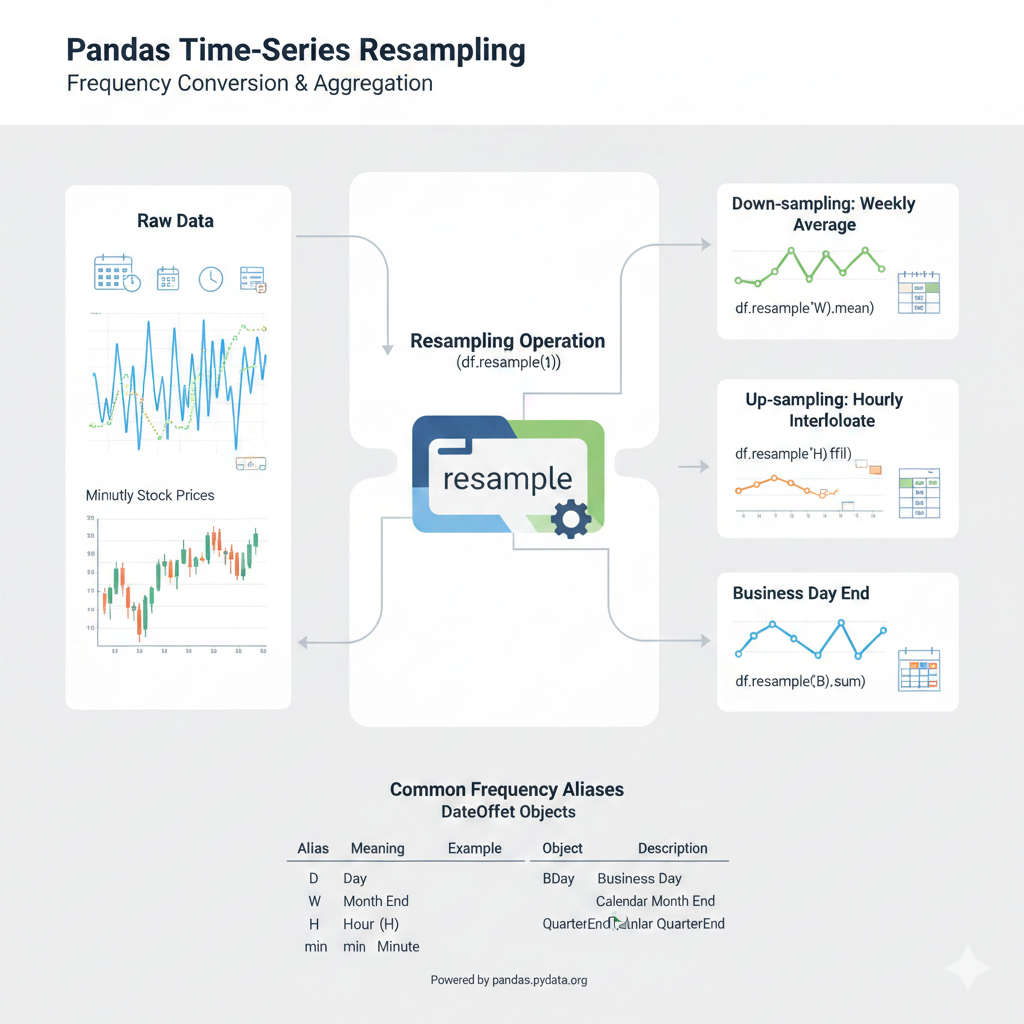
Sözdizimi:
resample() fonksiyonunun sözdizimi aşağıdaki gibidir. Parametrelerin açıklaması aşağıda Parametreler başlığında bulabilirsiniz.
DataFrame.resample(rule, axis=<no_default>, closed=None, label=None,
convention='start', kind=<no_default>, on=None,
level=None, origin='start_day', offset=None …
Cum 21 Kasım 2025
Tags:
assign() Metodu
assign() metodu, bir veri tablosu üzerinde çalışırken, tablonun orijinal halini bozmadan (değiştirilmezlik ilkesi) yeni bir sütun eklemek veya mevcut sütunları değiştirmek istediğinizde kullanılır.
Eğer elinizde bir satış tablosu varsa ve siz bu tabloya "Toplam Gelir" diye bir sütun eklemek istiyorsanız, assign() metodu ile bu yeni sütunu hesaplayıp ekleyebilirsiniz …
Continue reading »
Paz 16 Kasım 2025
Tags:
pyarrow String Türü ile Hızlanmak
Pandas'ta dizelerle (strings) mi çalışıyorsunuz ve beklediğinizden biraz daha yavaş olduğunu mu görüyorsunuz? Bu eğitimde, PyArrow'u kullanarak işleri nasıl hızlandırabileceğimizi öğreneceğiz.
Örnek olarak kullanacağımız dosyanın adı TDK_imla.txt. Bu dosya, satır başına bir kelime olacak şekilde toplam 76.183 kelime içeren bir imla sözlüğüdür …
Continue reading »
Paz 06 Temmuz 2025
Tags:
unique() ve nunique() Metotları
unique() Metodu
unique() Metodu, Veri Çerçevesinden benzersiz değerler tespit etmek, kategorik verileri analiz etmek veya yinelenen verileri tanımlamak için kullanılır.

unique() Metodunun Kullanımı
unique() Fonksiyonu bir NumPy dizisi döndürür. Bir sütundaki benzersiz (farklı) değerleri tanımlamak için kullanışlıdır ve bu, kategorik verilerle çalışırken veya benzersiz değerleri algılarken …
Continue reading »